naxsi
Whitelists
Whitelists are meant to instruct naxsi to ignore specific patterns in specific context(s) to avoid false positives.
ie. Allow the ‘ character in the field named term at url /search :
BasicRule wl:1013 "mz:$ARGS_VAR:term|$URL:/search";
Whitelists can be present at location level (BasicRule) or at http level (MainRule).
Whitelists have the following syntax :
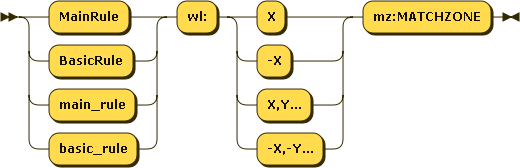
Everything must be quoted with double quotes, except the wl part.
Whitelisted ID (wl:…)
Which rule ID(s) are whitelisted. Possible syntax are:
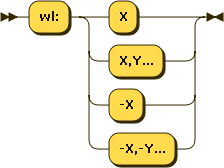
wl:0: Whitelist all ruleswl:42: Whitelist rule#42wl:42,41,43: Whitelist rules42,41and43wl:-42: Whitelist all user rules (>= 1000), excepting rule42
note: you can’t mix negative and positive ID(s) in whitelists
MatchZone (mz:…)
Please refer to Match Zones for details.
mz is the match-zone, specifying in which part(s) of the request the specified ID(s) must be ignored.
In whitelist context, all conditions specificied in the mz must be satisfied :
BasicRule wl:4242 "mz:$ARGS_VAR:foo|$URL:/x";
ignore id 4242 in GET var named foo only on URL /x
As for rules, $URL* in match-zone is not enough to specify the target zone.
Notes
- A zone (ARGS,BODY,HEADERS) can be suffixed with
|NAME, meaning the rule matched in the name of the variable, but not its content. RAW_BODYwhitelists are written just as anyBODYwhitelist, see Whitelists Examples- A whitelist can’t mix
_Xelements with_VARor$URLitems. ie:
$URL_X:/foo|$ARGS_VAR:bar : WRONG
$URL_X:^/foo$|$ARGS_VAR_X:^bar$ : GOOD
You can also whitelist by IP/CIDR and all the rules will not be blocked for these ips but logs will be generated. For more details look here: IgnoreIP and IgnoreCIDR